
Why data warehouse modernization?
The volume of data within organizations is experiencing rapid growth. As a result, organizations are eager to derive insights from this data and ensure its accessibility to all users. However, traditional systems pose several challenges in terms of complexity, inflexibility, and inadequate scalability to meet the increasing demands for data analysis. Consequently, customers often face difficulties such as performance at scale, rising costs, and delays in accessing data faster. These are some of the common concerns of customers, which prompt them to explore the option of modernizing their data warehousing solutions.
A modern data warehouse is expected to fulfill the core functionalities of a traditional data warehouse, such as supporting business intelligence analytics with high performance. However, it should go beyond that. It should enable organizations to scale to petabytes of data and facilitate the accessibility of analytics to a vast user base, even those without prior database management experience.
Furthermore, a modern data warehouse should unlock new possibilities for diverse applications. For instance, it should offer the capability to directly run machine learning algorithms on the data stored in the data warehouse. Additionally, it should facilitate analytics across various data sources, including data lakes, operational databases, and streaming data. Once access to this vast array of data is established, the data should be consistently shared throughout the organization. Another emerging application involves third-party collaboration.
Amazon Redshift
Over the past decade, AWS has been at the forefront of reinventing the data warehouse landscape. It all began in 2012 with the launch of Amazon Redshift, the first cloud-based data warehouse. Redshift introduced a range of critical capabilities that have revolutionized the field, including the ability to directly query data lakes and operational databases, in-database machine learning, and concurrency scaling. These capabilities have enabled many customers to extract valuable insights and gain a competitive edge from their extensive data resources. At the core of Redshift's innovation lies its exceptional price performance, made possible through the combination of distributed data processing, vectorization, materialized views, advanced query optimizations, and efficient encoding techniques. By leveraging these capabilities, Redshift delivers up to 5x better price performance compared to the alternative data warehouse systems.
Data warehouse migration with Amazon Redshift
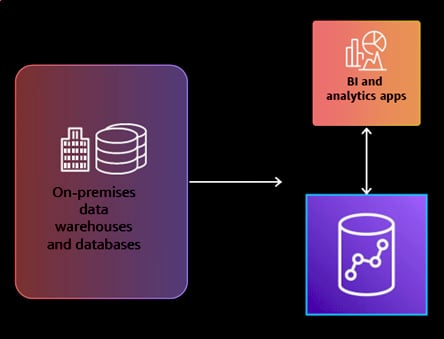
The initial step in modernizing a data warehouse involves migrating from an on-premises system to Redshift or any cloud-based solution. Redshift provides robust ANSI SQL capabilities and seamless connectivity with various BI and analytics tools. Moreover, AWS offers a user-friendly application development API called the Data API, which allows developers to easily build analytic applications using languages such as Python and Node.js. Redshift supports various data types, including semi-structured and spatial data.
To facilitate smooth migrations, AWS has recently introduced additional SQL capabilities to Redshift, such as the MERGE, a SQL syntax, and OLAP functions like Roll-up, Cubes, and Grouping sets. These enhancements ensure that Redshift possesses comprehensive SQL capabilities for seamless migrations. Security is critical when adopting data warehouses across diverse use cases, and Redshift provides built-in security features at no additional cost. These features include compliance notifications, the option to run Redshift within your own Virtual Private Cloud (VPC), granular authorization at the row and column level, and a newly introduced feature called dynamic data masking, which protects sensitive data.
Data warehouse migration can be a challenging task that requires various tools. One such tool is the AWS Database Migration Service (AWS DMS), which facilitates moving data from on-premises systems to the cloud. Additionally, the AWS Schema Conversion Tool (AWS SCT) is involved in mapping an existing on-premises data warehouse database to Redshift, considering any syntax or semantic disparities. AWS recognizes the significance of a robust partner ecosystem and provides a comprehensive network of partners who can help accelerate data warehouse migrations.
Amazon Redshift Serverless
Scaling analytics within the organization involves making the data accessible to all users, including those without data warehouse management experience. It also requires catering to diverse workloads, regardless of their dynamic and variable nature. To address these challenges, AWS has introduced Amazon Redshift Serverless. With the serverless model, there is no need to manage clusters. Redshift automatically provisions compute resources and scales them based on workload demands, ensuring optimal performance. It takes care of essential tasks such as patching, version upgrades, backups, and recoveries, freeing you to focus on deriving insights from your data. In Redshift Serverless, you only pay for the actual usage of resources. For instance, if you have a sporadic workload that runs for 10 minutes within an hour, you are billed solely for the 10 minutes of capacity used during that period.
Data lake querying with Amazon Redshift
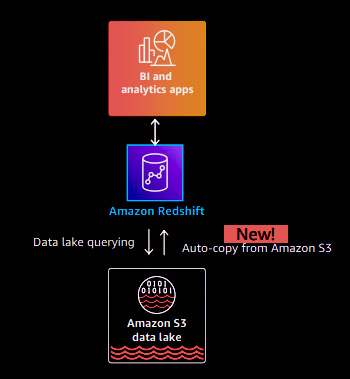
Amazon Redshift offers a flexible approach to data management. You have the option to adopt a data warehouse-centric approach, where all your data is stored in Redshift. Redshift utilizes managed storage, backed by S3, to ensure efficient data handling. Alternatively, you can choose a hybrid approach, storing some data in open formats and some in Redshift. Redshift supports both of these use cases effectively.
With Redshift, you have the advantage of directly querying data in open formats within the data lake, achieving high performance, and combining it with data in your data warehouse. AWS has recently introduced a new capability that allows for ad hoc queries on the data lake. Additionally, data ingestion from the data lake to Redshift is made easy without complex pipelines. This leads to zero ETL (Extract, Transform, Load) vision, where data is automatically loaded into Redshift once the setup is complete. Redshift also integrates with AWS Glue Catalog and Lake Formation, enabling centralized governance and enhanced security measures.
Machine learning and advanced analytics with Amazon Redshift
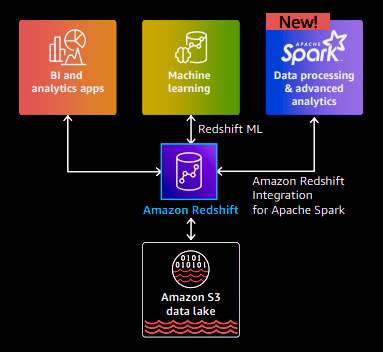
A modern data warehouse should offer expanded capabilities such as machine learning and data processing. Amazon Redshift provides built-in machine learning capabilities within the database and integrates with Amazon SageMaker, a fully managed machine learning service. This integration enables you to leverage SQL to create, train, and deploy models. With Redshift's machine-learning capabilities, you can develop your models. For instance, if you have models trained outside Redshift using SageMaker, you can bring them into Redshift for in-database inference. This allows you to utilize the power of Redshift for efficient model execution. In addition to machine learning, AWS has introduced a new capability to integrate Redshift with Apache Spark, a distributed processing framework. This integration simplifies and accelerates the execution of Apache Spark applications on top of data in the data warehouse. To get started, you can leverage a packaged and certified integration offered by Amazon EMR or AWS Glue. This enables you to develop Spark applications using the native programming model of Spark.
Real-time analytics with Amazon Redshift on streaming data
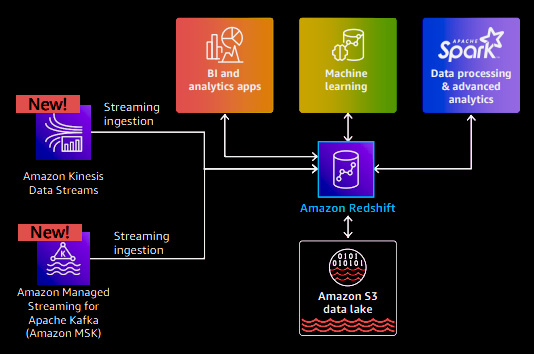
As organizations increasingly prioritize data-driven decision-making, there is a growing need for real-time analytics. Because they want to gain insights into their business drivers, enhance sales, reduce costs, and improve customer experiences. To accomplish these objectives, Amazon Redshift integrates with the rest of the AWS ecosystem to enable real-time analytics. AWS has recently introduced a streaming ingestion capability that allows users to ingest high volumes of streaming data into Redshift, making it available for analysis within seconds. This integration is designed to simplify the process, eliminating the need to build any pipelines or deal with the complexity of the ETL pipelines. Users can leverage familiar SQL commands. By creating a materialized view using SQL, users can connect it to either Amazon Kinesis Data Stream or Amazon MSK (Managed Streaming for Apache Kafka). Adding new data to the Kafka or Kinesis streams automatically updates the materialized view with the latest data, ensuring real-time insights are readily available.
Analytics with Amazon Redshift on transactional data
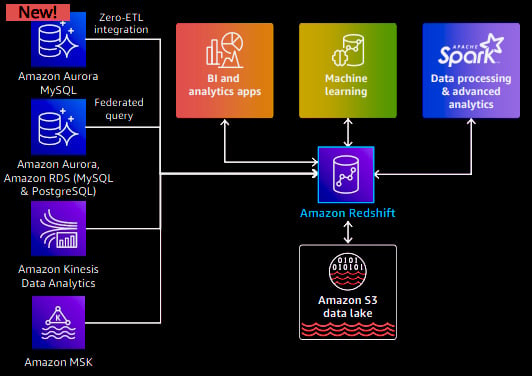
Amazon Redshift offers seamless integration with operational databases, allowing for direct analytics on transactional data. For instance, Redshift has introduced federated querying, which enables users to query Amazon Aurora and Amazon RDS (MySQL and PostgreSQL) databases directly from Redshift and perform joins with data in the data warehouse. Federated querying proves valuable for ad hoc queries and data exploration scenarios. Furthermore, AWS has introduced a zero-ETL integration between Amazon Aurora and Amazon Redshift. This integration enables near real-time analytics on petabytes of transactional data by joining data from multiple Aurora databases into a single Redshift instance. Continuous data replication from Aurora ensures that the latest information is available in Redshift within seconds.
Data sharing with Amazon Redshift
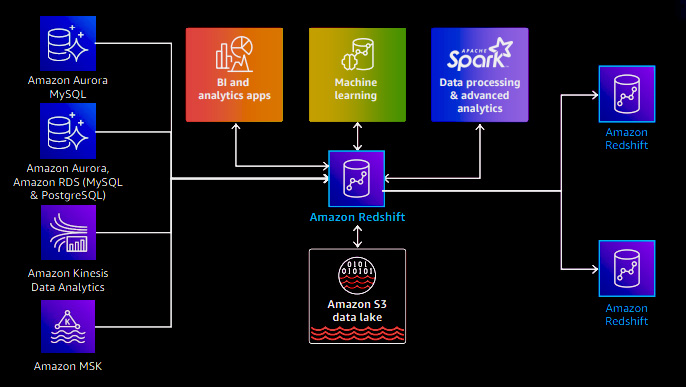
Once the data is collected from various sources, such as the data lake, streams, and operational databases, the next step is to ensure its consistent availability throughout the organization. With Redshift data sharing, you can share live and transactionally consistent data across multiple Redshift data warehouses. These data warehouses can reside within the same account, different accounts, or even across different regions. The key aspect is that you are not duplicating or moving the data; instead, you collect the data from its sources and make it accessible across the organization. Data sharing empowers customers to adopt flexible, multi-cluster, and data mesh architectures.
Data sharing integration with AWS Lake Formation
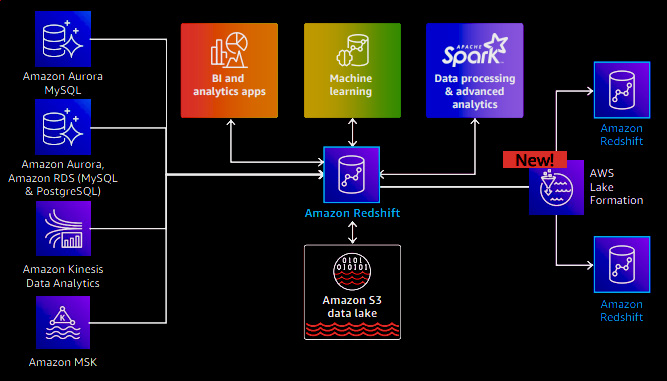
AWS recently announced an integration of data sharing with AWS Lake Formation, which facilitates direct data sharing between data warehouses. Users can now discover and query data from AWS Lake Formation. This integration offers the advantage of centralized management, allowing users to specify access control and govern data access from Lake Formation in a unified manner across all data-sharing consumers.
Amazon Redshift and AWS Data Exchange integration
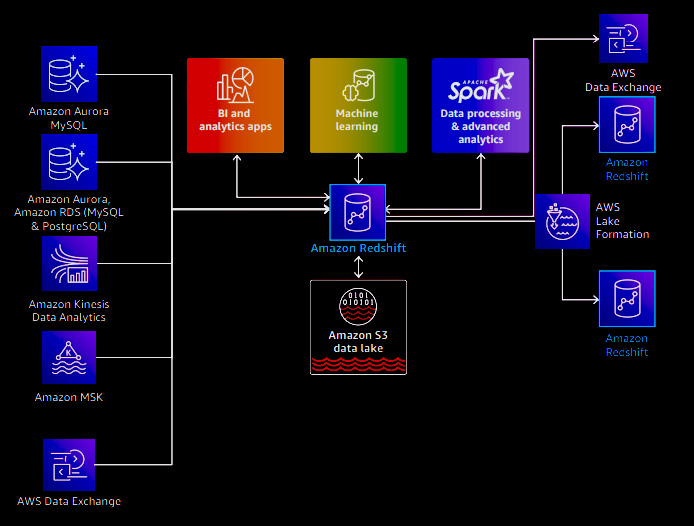
Redshift integrates with AWS Data Exchange (ADX) to enable collaboration with third-party datasets. With ADX, you can discover, subscribe to, and consume these external datasets and combine them with the data in your data warehouse. Furthermore, it allows you to share the data stored in your data warehouse with other stakeholders within your business ecosystem. The integration with AWS Data Exchange is built on data sharing. It enables live data access without needing ETL processes, data copies, or data movement. Data Exchange manages subscriptions, payments, and licensing aspects related to third-party collaborations. This integration simplifies working with external datasets, fostering collaboration and data-driven insights within your organization.
Resources:
Amazon Redshift
The Business Value of Amazon Redshift Cloud Data Warehouse
AWS Skill Builder
Amazon Redshift What's New
Reference:
AWS re:Invent 2022
