Why database resiliency matters?
In the context of IT systems, resilience pertains to the capacity of a workload, which comprises various resources and code to provide business value, such as customer-facing applications or backend processes to respond and recover from failures. A workload may consist of a subset of resources within a single AWS account or extend across multiple accounts and regions.
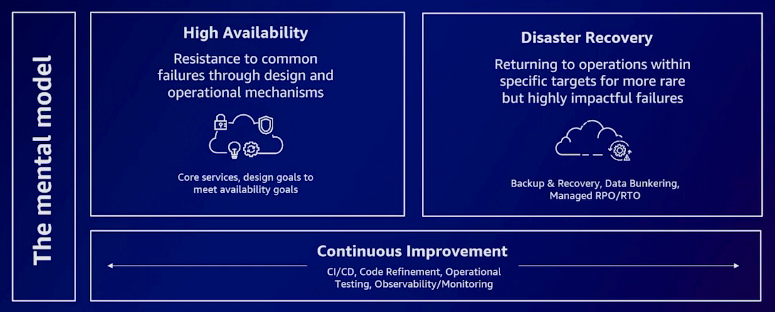
Three crucial mental models help in understanding resilience: high availability, disaster recovery, and continuous improvement. High availability revolves around building a highly available system that can resist common failure modes. Disaster recovery focuses on devising strategies to restore your system in the event of rare failure incidents. On the other hand, continuous improvement emphasizes the ability to swiftly implement changes following a failure, ensuring a prompt recovery process.
Strategies for disaster recovery
Disaster recovery consists of various strategies: backup and restore, pilot light, warm standby, and active/active. Understanding these approaches in terms of their Recovery Point Objective (RPO) and Recovery Time Objective (RTO) is crucial. RPO indicates the data loss from the time of the failure-causing event, while RTO represents the recovery duration after such events. By understanding the RPO and RTO, one gains insights into the amount of data at risk and the recovery timeline.
Backup and restore: The backup and restore strategy generally has a higher RPO and a longer RTO. This implies a slight data loss and a lengthy recovery process. When restoring a backup, the data available is only up to the backup time, resulting in potential data loss between the event and the backup creation. Consequently, the RTO, representing the time required for restoring the backup, can also be relatively longer.
Pilot light: The pilot light strategy has significantly reduced RTO and RPO, usually measured in dozens of minutes rather than hours required for backup and restore. In this approach, data is live, while computing resources might not be operational, limiting the ability to serve data to your workload. Although slightly more expensive, this strategy substantially improves the application's recovery time.
Warm standby: A warm standby scenario resembles what you might traditionally consider an active and passive environment. In this setup, data is replicated into multiple availability zones or regions. However, some scaling might be necessary to enable your application to start consuming those availability zones or the warm standby setup. While it comes with a slightly higher cost, this approach significantly reduces RTO and RPO, measured in single-digit minutes.
Active/active: This strategy maintains the application's operation across both sets of replicated workloads. With this approach, you can achieve near-zero or zero downtime, and your users might not even realize that a failure has occurred. Though it comes at a slightly higher cost, this method is essential for mission-critical workloads to ensure robust availability and uninterrupted service.
AWS Regions and Availability Zones (AZs)
AWS has 31 regions worldwide, covering countries like Australia, Canada, Israel, New Zealand, and the United States. In total, there are approximately 99 availability zones. Each region comprises at least three availability zones. However, availability zones are not the smallest unit; they are made up of data centres separated by a meaningful distance. Despite the separation, these data centres are strategically close enough to be regarded as logical data centres.
Building a modern data strategy
A modern data strategy begins with migrating to the cloud and adopting an infrastructure that provides the required scale at optimal costs while reducing operational overheads. One can implement modern data strategies by eliminating the management of backups and infrastructure. AWS facilitates this by offering a range of purpose-built databases, such as Amazon Neptune, Amazon DocumentDB, Amazon Aurora, Amazon DynamoDB, and many others.
Amazon Aurora concepts for availability
Amazon Aurora provides a purpose-built database solution, enabling organizations to future-proof their applications. With AWS database services handling essential management tasks like server provisioning, patching, and backups, teams can focus on more value-added work. Many enterprises are leveraging AWS migration system programs to optimize their database migrations, with over 800,000 databases migrated so far.
Amazon Aurora Backups and Point-in-time recovery
Aurora's backup capabilities enable point-in-time recovery for your database instance. This means you can restore your database to any second within the retention period, up to the last five minutes. The automatic backup retention period can configure for up to 35 days.
Automated backups are stored in Amazon Simple Storage Service (Amazon S3), designed for 11 nines of durability. Amazon Aurora's backups are automatic, incremental, and continuous, ensuring efficient data protection. They have no impact on your database performance due to the separation of the storage layer from the compute layer.
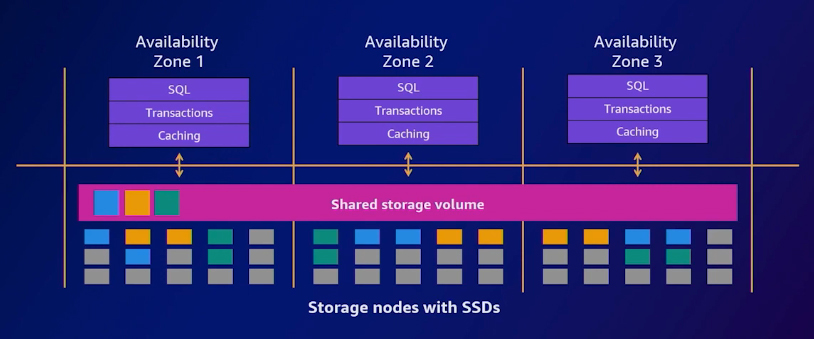
Amazon Aurora availability design pattern
Within each availability zone, separate compute resources are present. When an instance failure occurs, Aurora leverages Amazon RDS's multi-AZ technology to automatically failover to one of the up to 15 replicas you have set up across three availability zones. In cases where no replicas exist, a new Aurora database instance is created automatically. The separation between storage and computing in Aurora offers a significant advantage. You don't have to wait for the database to hydrate. Instead, the database instance swiftly attaches to the storage layer and resumes operations, ensuring minimal downtime and efficient failure recovery.
Fast cross-Region disaster recovery with Amazon Aurora Global Database
Aurora designs to support globally distributed applications, allowing a single Aurora database to extend across multiple AWS regions. It seamlessly replicates your data without impacting database performance. This design enables fast local reads with low latency in each region while providing comprehensive disaster recovery for region-wide outages.
If your primary region encounters performance issues or experiences an outage, you have the flexibility to promote one of the secondary regions to handle read-write responsibilities. Notably, an Aurora cluster can recover in under one minute, even during a complete regional outage. This exceptional capability gives your application an impressive one-second RPO and an RTO of less than a minute, providing solid foundations to build your application.
Global reads with low replication latency with Amazon Aurora Global Database
Global databases offer the ability to scale your applications worldwide by strategically placing your database close to your users' locations. This approach ensures your applications enjoy rapid data access, regardless of the number and location of secondary regions. The typical replication latencies between regions are below one second. To achieve even greater scalability, you can create up to 16 replicas in any region, all of which remain continuously up to date.
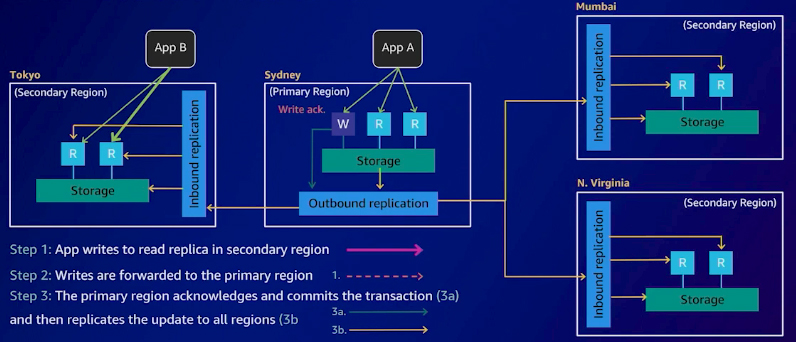
Amazon Aurora design pattern: Write Forwarding with Global Database
In a multi-region design, handling writes involves a strategic process. Let's consider an example where an application runs in Sydney and Tokyo regions. The readers in the secondary Aurora database cluster in Tokyo accept reads that are replicated from the Sydney region. Now, with the addition of two more secondary regions, we have a total of three secondary regions and one primary region. This setup allows people in other regions to write to this database.
With global write forwarding, you can effectively manage these writes. When a write request receives in a reader node from another region, it forwards to the region currently serving as the primary. Once this occurs, the writer acknowledges the receipt of the write request. Subsequently, the primary region commits this information to the transaction log and then replicates it to all the secondary regions. This streamlined process allows your applications to have read-and-write functionality in a global relational database.
Amazon DynamoDB concepts for availability
At its core, DynamoDB is designed to deliver exceptional high availability, durability, and consistent low latency, often in the single-digit milliseconds of performance. Running on a fleet of AWS-managed servers equipped with solid-state drives, DynamoDB creates an optimized, high-density storage platform. This design decouples table size from performance and eliminates the need for the working data set to exist in memory while ensuring consistent low-latency responses to queries. As a managed service, DynamoDB abstracts the details of its underlying architecture from the user. Even within a single region, DynamoDB guarantees an impressive five nines (99.999%) of availability.
Amazon DynamoDB backup and restore
On-demand backups in DynamoDB offer a convenient solution for creating full backups of tables, enabling data archiving to meet corporate and government regulatory requirements. Whether your tables contain just a few megabytes or hundreds of terabytes of data, on-demand backups can be executed without impacting the performance and availability of your applications.
On-demand backup processes backup requests within seconds, eliminating the need to worry about backup schedules or lengthy job execution. Similarly to Aurora, DynamoDB also provides point-in-time recovery, allowing you to choose specific recovery periods down to the last 35 days. All backups are automatically encrypted and catalogued, ensuring easy discoverability. You can perform backup and restore operations with a single click in the AWS console or a single API call.
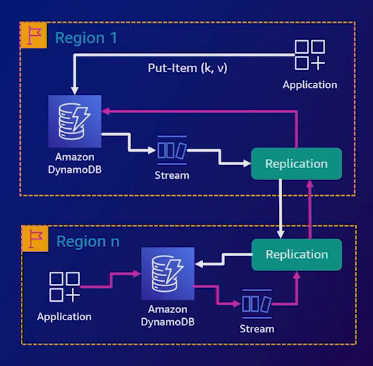
Multi-Region, multi-active capabilities
DynamoDB Global Tables offer a powerful multi-region, multi-active solution that enables you to write locally to each region, resulting in fast writes that are replicated to other regions. This approach provides strong consistency within the local region and eventual consistency in other regions. Conflicts are handled using a "last-write wins" process. The ultimate goal is to ensure that the global database eventually reaches an identical and consistent state across all regions.
Leveraging AWS's global footprint, Global Tables offer a fully managed, multi-region, and multi-active database, delivering fast and efficient local read and write performance for massively scaled global applications. With automatic replication of your DynamoDB tables across your chosen AWS regions, Global Tables eliminate the complexity of replication and resolve conflicts, freeing up your time to focus on creating the most impactful business value for your customers.
Use case: Disney+
Disney+ is one of the largest global online video streaming platforms, housing a vast collection of content from Disney, Pixar, Marvel, Star Wars, and National Geographic. Since its launch in November 2019, Disney+ has been on a multi-region expansion journey. To support this expansion, Disney+ chose DynamoDB as their database solution. With DynamoDB, Disney+ can replicate their database tables in new regions as they expand their services.
Reference:
AWS Events – AWS Summit ANZ 2023
