
Data Resiliency
Data stands as a key asset for most businesses. Customers depend on data availability to conduct their business operations. When considering data resiliency, the focus is on ensuring application availability despite intermittent failures, partial outages, or system overload. Two critical concepts emerge in this context: high availability and disaster recovery.
High Availability
High availability refers to the concept that an application should remain operational in a component failure. Customers require constant uptime for their applications. In the event of a server failure or network outage, applications must degrade gracefully. This means they should be capable of recovering from outages or sudden spikes in system load, ensuring uninterrupted service delivery.
Disaster Recovery
We expect applications to recover gracefully from various situations. Yet, there might be instances where an entire region experiences an outage because of a power failure or a natural disaster such as an earthquake. It's crucial to prepare for such scenarios. In such events, two key terms come into play: Recovery Point Objective (RPO), indicating the acceptable data loss for your applications and business, and Recovery Time Objective (RTO), indicating the expected timeframe for application recovery and business continuity. Guided by these terms, strategic planning for data resiliency becomes imperative. The choice of resilience strategies depends on your specific use cases and the tolerance levels of your business for potential losses.
Business impact of resilience
Research indicates that customers have suffered significant losses, including revenue, business, and reputational damage, due to inadequate consideration of data resiliency and availability strategies. For example, according to an IDC survey, top Fortune 1000 applications have incurred losses amounting to billions due to neglecting data resiliency measures. However, organizations prioritizing data resiliency as a fundamental strategy from the start can potentially realize cost savings.
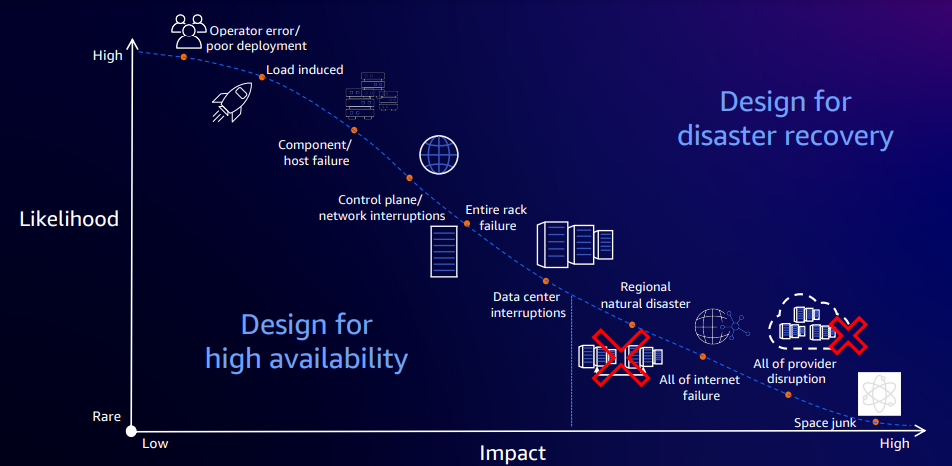
Data resiliency planning: Failure scenarios
When considering data resiliency strategies, it's crucial to consider potential failure scenarios. Among the most common are human errors, network component failures, and server overloads leading to system failure. In such cases, designing for high availability is essential. However, there may arise catastrophic situations where the entire application infrastructure collapses. While your focus is on designing for high availability, it's equally crucial to consider disaster recovery as the complementary aspect. It's important to prepare for both scenarios, as the choice between them relies on the criticality of your application.
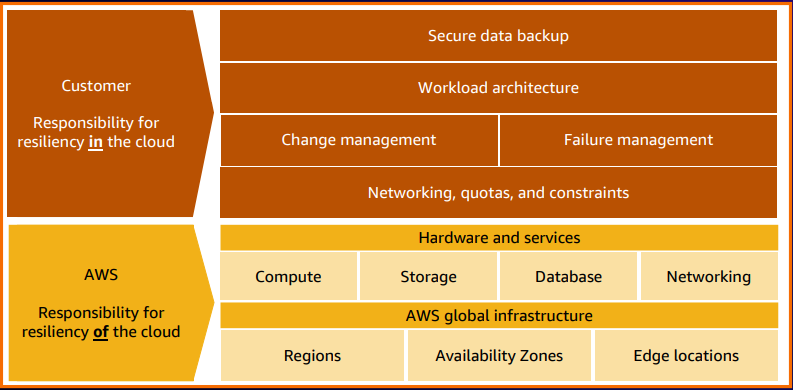
Shared responsibility model for data resiliency
AWS uses a shared responsibility model for data resiliency. In this model, AWS assumes responsibility for ensuring the resiliency of the underlying infrastructure where applications are hosted. This includes overseeing the resiliency of regions, availability zones, edge locations, and various infrastructure components such as computing, storage, databases, networking, and hardware systems utilized by applications. However, it's essential to note that this is a shared responsibility model. Customers who develop applications on AWS infrastructure are accountable for enhancing the resiliency of their applications, configuring backup plans, implementing policies to support application resilience, and setting up security measures to safeguard access to the applications.
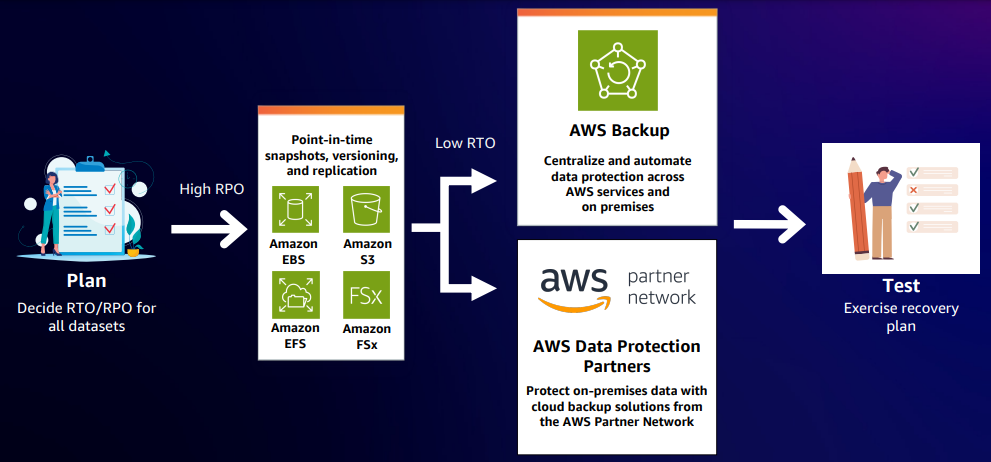
Data resilience using native capabilities
AWS offers a robust storage portfolio containing block storage, object storage, and file storage solutions. Customers can leverage native capabilities or utilize services like AWS Backup, Elastic Disaster Recovery, and AWS Resilience Hub to ensure the resilience of their applications. First, it's important to assess your RTO and RPO objectives. This involves determining the acceptable losses your business can endure concerning disaster recovery and application availability. Based on these considerations, various tools are available to create disaster recovery and application resilience plans. These tools include point-in-time snapshots, backup and recovery mechanisms, and features such as versioning and replication, all aimed at ensuring the resilience of your data. If your AWS setup involves multiple resources, AWS Backup offers a seamless solution for creating backup policies covering all your application data. You can also explore third-party and partner products available on AWS to support application resilience. However, testing is important. It's essential to validate your disaster recovery plan to ensure its effectiveness. Moreover, AWS provides extensive guidance through its well-architected pillars, offering insights into architecting resilient applications capable of withstanding failures.
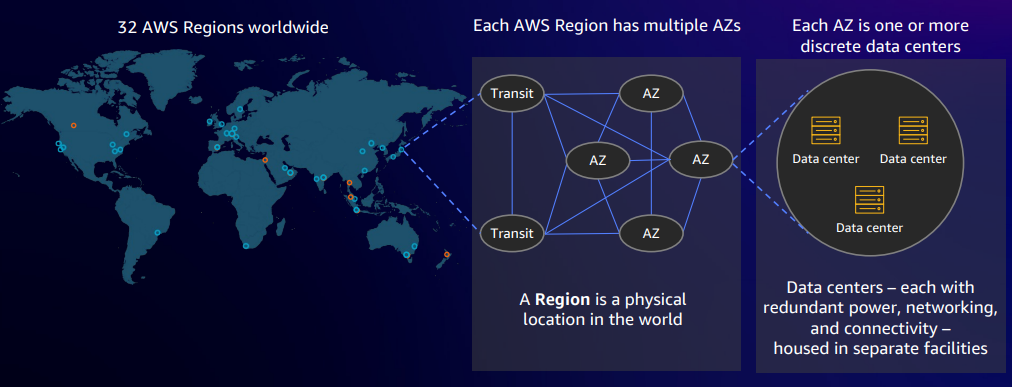
High Availability
High availability is a fundamental design principle for AWS when constructing its underlying infrastructure, and it tries to eliminate any single point of failure within its systems. AWS achieves this by provisioning 32 regions worldwide, containing approximately 96 availability zones. These availability zones are designed to avoid single points of failure where operations within one availability zone remain unaffected by issues occurring in another zone. Customers can take advantage of this architecture by deploying their applications across multiple regions and availability zones. This strategy ensures that applications remain available and operational, particularly in the event of a disaster.
Disaster Recovery
When it comes to disaster recovery, there are four distinct strategies to consider. However, determining the best strategy is not a one-size-fits-all scenario. It depends on your specific use case and the acceptable parameters for disaster within your organization. Each strategy has its trade-offs between cost, complexity, and the RTO, essentially, how long your system can afford to be down. It's critical to understand the business impact of downtime. This involves assessing the financial implications of being offline for varying durations, whether minutes, seconds, or days. Invariably, there's likely an application that aligns with each of these categories.
When considering DR strategies, several options are available based on your priorities and resources. Firstly, there's the traditional method of backup and restore. This is typically the most cost-effective approach but comes with a longer RTO. Next is the warm standby, a concept familiar to those with on-premises setups. In this scenario, an application stack is provisioned in another region or data center at a lower capacity. In a disaster, you can transition operations to the designated region or data center and scale up quickly. However, there's a trade-off involved. While this strategy offers rapid scalability and resilience, it does incur additional costs. The pilot light can be considered a cost-optimized version of warm standby, where data replication occurs in another region without the full application stack provisioned. It's suitable for backend applications with tolerable downtime. Multi-region active/active configuration is for your core business-critical applications. Consider scenarios like operating a trading exchange or a ticketing system, where even a mere two seconds of downtime could translate into significant financial losses. Therefore, investing in a robust DR strategy is important despite its higher cost.
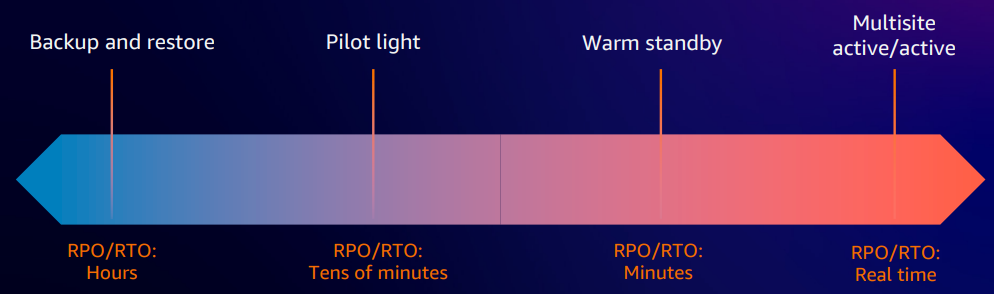
Backup and restore
This strategy is one of the more traditional approaches to disaster recovery. It involves customers taking backups of their data and securely storing them, often in a vault or another protected environment. Typically, this method is employed for non-core business applications that can afford to be offline for an extended period, such as test environments or non-critical applications like HR software that doesn't handle payroll. This type of DR strategy is also utilized for ransomware recovery scenarios. In a ransomware attack, recovering files from clean backups, potentially from a week or two ago, ensures the restoration of uncorrupted data. While not directly related to disaster scenarios, customers can also utilize this approach for compliance use cases. Industries such as healthcare or finance are often subject to government regulations requiring them to retain data for extended periods.
Pilot light
Pilot light is a cloud-native approach to disaster recovery, ideal for semi-critical business applications. It's tailored for scenarios where you can tolerate an RTO ranging from 15 minutes to an hour, ensuring minimal downtime. In a pilot light setup, your data is replicated in another region, but the non-critical components of your application stack may not be replicated. In the event of a disaster, there's a short delay while you provision and scale up these additional resources, typically around 15 minutes. However, this strategy is well-suited for applications that can withstand being offline for up to an hour without significant business impact. Pilot light offers a cost-optimized solution.
Warm standby
Warm standby builds upon the pilot light concept by provisioning more application components. In this setup, a secondary set of your application stack is provisioned in another region but running at a lower scale. While this results in increased costs compared to the pilot light, it offers a lower RTO. Warm standby is suitable for core applications with about zero to 10 minutes of downtime. To illustrate, consider the standby mode on your laptop: when you close it, it goes into standby, and when you reopen it, there's a brief delay before it's fully operational. The key difference between warm standby and the pilot light is that you don't need to provision EC2 instances or load balancers upon activation; they're already in place, and traffic can redirect to the standby region. However, there's still a short delay, around 10 to 15 minutes, for these resources to scale up to support increased traffic. This strategy is advantageous for applications where the financial impact of a brief downtime outweighs the expenses of maintaining a warm standby site.
Multi-region active/active
The multi-region active/active setup represents the highest-cost disaster recovery strategy, as it involves running two active regions with data and resources replicated between them. Typically, customers implement this in an active-passive strategy, directing all production traffic to one region while maintaining a DR region. In the event of a disaster, they can switch over to the DR region, ensuring zero downtime. This approach is undeniably expensive, as it requires running two regions simultaneously. However, the cost is justified for certain customers, particularly those in industries where even a fraction of downtime is intolerable, such as high-frequency trading platforms where millions of transactions occur in microseconds. Even a brief downtime can lead to significant financial losses in such critical business scenarios, potentially reaching millions of dollars.
Overview of AWS Backup
AWS Backup is a fully managed, policy-based service designed to centralize and automate data protection processes across AWS and hybrid environments. With AWS Backup, you can consolidate your backup management tasks, ensuring efficient handling of lifecycle policies and scheduling. Additionally, AWS offers robust analytics and reporting features, empowering users to gain insights into their backup activities and optimize their protection strategies. By centralizing backup management, AWS Backup simplifies administration across multiple AWS resources.
AWS-native solution for centralized data protection
Customers frequently express frustration with managing their data protection in silos. These silos involve overseeing data protection for cloud, hybrid, and AWS resources. To illustrate this within a customer's application deployment, consider the following: On the left side, you have the traditional on-premises infrastructure, where customers run their applications within their own data centers. Here, they typically employ backup vendor software to handle data protection tasks and store backups within their data centers. In a hybrid scenario, customers run their applications within their own data centers but seek to store their backups in a cloud destination. Cloud-native applications involve customers deploying and storing their backups directly in the cloud. AWS Backup is ideally suited for hybrid and cloud-native environments, enabling customers to set up centralized policies across all AWS resources and some of their hybrid resources. Leveraging storage gateways facilitates maintaining a consistent policy, assuring that data is protected without the need for redundant efforts. This approach minimizes the risk of errors associated with repetitive tasks.
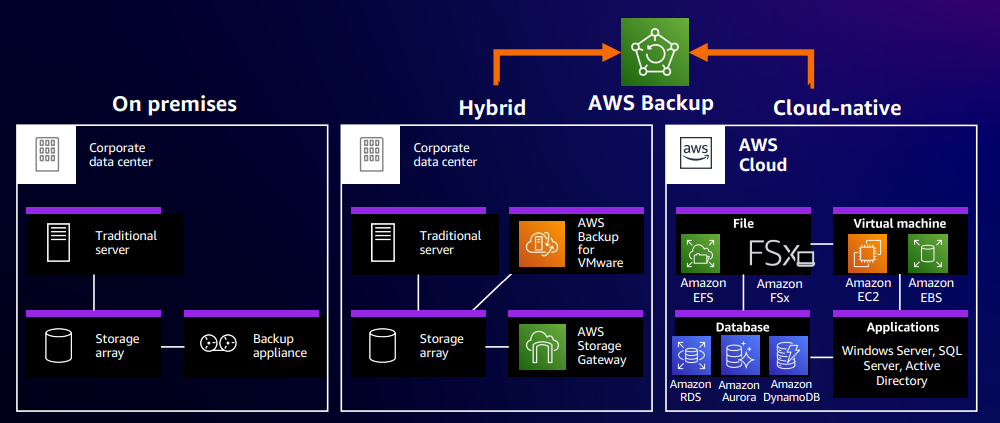
AWS Backup use cases
Cloud-native backups: When managing multiple resources within AWS, it's crucial to establish a systematic and consistent backup scheduling mechanism driven by policies. This ensures confidence in the regularity of backup operations. AWS Backup offers a straightforward solution: configure a simple backup plan tailored to your requirements. With this plan in place, you can automate the scheduling of backups.
Compliance and governance: It provides the capability to ensure the immutability of your backups. Furthermore, AWS Backup enables you to generate comprehensive reports on the status of your backups, which is crucial for meeting regulatory obligations.
Disaster recovery: Depending on your RTO and RPO objectives, you can use a backup and recovery strategy as a DR strategy.
Ransomware recovery: With AWS ensuring the immutability of their backups, if your data falls victim to a ransomware attack and becomes compromised by malicious actors, you can restore it to a version that contains the correct, uncorrupted data. This enables you to restore your systems to a state before the attack.
Reference:
AWS Events
