
Building a smart application using an LLM
Let's assume you have an existing application that your support team uses to manage interactions between customers and support agents. The support supervisor wants to obtain summaries of these engagements to support coaching and improvement efforts. From an architectural perspective, your application includes a front-end user interface running in users' browsers, while the application logic and data store operate on AWS. To integrate with a Large Language Model (LLM), you just need to call the Amazon Bedrock API and process its response.
Code
First, create and initialize a Bedrock client, and then write a prompt in natural language, asking the LLM to summarize the attached engagement. Then, create a configuration object for the model invocation. Finally, call the invokeModel method, which communicates with the LLM in Amazon Bedrock and retrieves a response. With this, your application is now integrated with an LLM.

There are two key points to highlight in this code sample. First, you can influence the output of the LLM by modifying the natural language prompt, a technique known as prompt engineering. Second, the choice of models is critical. Depending on your use case, you need to balance three factors: the quality of the model's response, the response time for users, and the cost of using the model. Therefore, selecting the model that best fits your requirements is important. Also, new LLMs are emerging and improving at an unprecedented pace, so you should ensure your system is flexible to switch to a more suitable model as new models become available.
Foundation models in Amazon Bedrock
Amazon Bedrock offers a range of foundation models, allowing you to choose the one that best suits your needs. But how do you determine which model works best for your use case? Amazon Bedrock provides a model evaluation feature that covers common NLP tasks. This evaluation comes in two forms: automatic and human workers.
Automatic evaluation: With automatic evaluation, Bedrock automatically calculates performance and quality metrics for the NLP tasks you are evaluating. This approach is ideal for large-scale benchmarking across multiple models.
Human evaluation: You can use your own team or rely on AWS-managed teams for human evaluation. This approach is well-suited for low to medium-volume evaluations, particularly when comparing two models head-to-head, helping you finalize your model selection.
Change to a different LLM
Model evaluation helps you find the best model for your use case. Once you have selected a new model, all you need to do is update the model ID to reflect your choice. For example, if you initially started with Amazon Titan but, after evaluation, decided to switch to Anthropic Claude-v2, simply update the model ID to point to the new model. Then, adjust the configuration to align with the requirements of the new model.
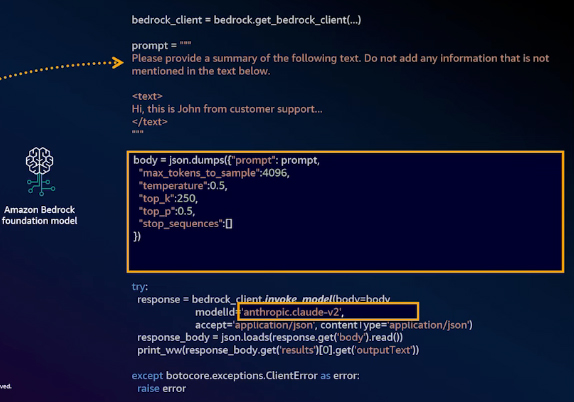
To achieve the best model response quality, you may also need to adjust the prompt slightly. Each LLM has its own preferences for how questions should be asked. For example, Anthropic Claude-v2 typically performs better when prompts include specific tags, such as human and system.
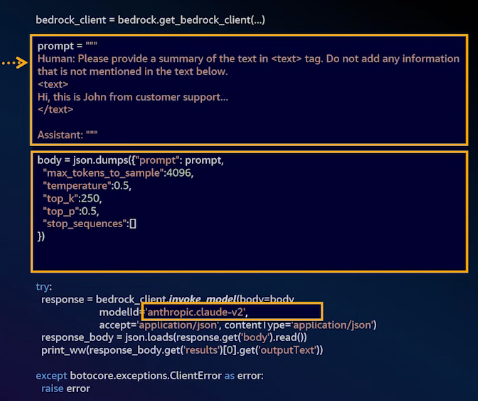
Once you have built your LLM-powered application, you are ready to share it with customers to gather feedback. However, security and privacy are often the primary concerns when introducing new technologies.
Security and privacy
With Amazon Bedrock, you maintain full control over your data. The data you send to Bedrock will not be used to improve models or shared with third-party model providers. Bedrock also adheres to common compliance standards. Also, if your organization is subject to standards such as ISO, SOC, or CSA STAR Level 2, using Bedrock can simplify your auditing process, thanks to the shared responsibility principle when using AWS services.
Include your own documents
When you release your application to internal or external users, they will likely ask that your application have knowledge of your organization and documents. However, all foundation models are trained using data from the internet, not your private data or documents. If you ask one of these models about your organization or documents, it doesn't know the answer or may generate incorrect information. To address this, assume you are building a virtual assistant for your support team to quickly find support documents and assist customers more effectively. To meet this need, your application must be able to process and utilize your organization's data, ensuring it remains up-to-date. When your support team asks a question in natural language, the application should perform a natural language search based on the semantic meaning and keywords. It should then provide relevant answers that the support team can use directly while also citing the source of the information.
Retrieval Augmented Generation (RAG)
One emerging approach to solve this problem is called Retrieval Augmented Generation (RAG). RAG is a pattern not tied to any specific LLM. In fact, you can implement RAG with any LLM, where the data store that holds your organization's data is separate from the LLM itself. This data store can be managed and orchestrated within the application layer. How does this RAG work?
Retrieval Phase
First, you need to optimize your data for RAG. In the data ingestion flow, you start by retrieving your documents from the data source. Then, you split the documents into smaller, meaningful chunks and pass them through an embedding model to convert those chunks into vector embeddings. These embeddings are stored in a vector-based database for easy indexing and efficient searching. At runtime, when a user asks a question in natural language within your smart application, the application will first use the same embedding model to embed the question. It will then perform a semantic or hybrid search against the vector data store to retrieve the most relevant documents.
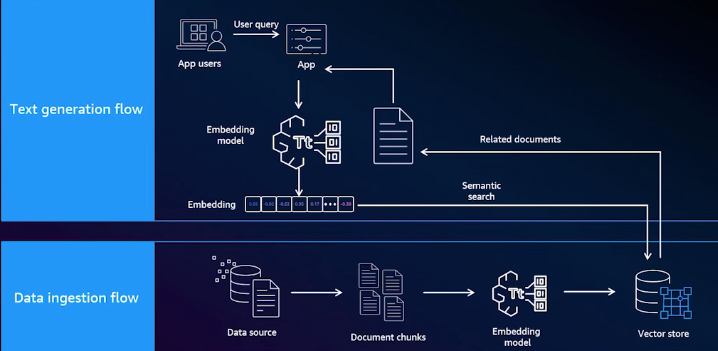
Augmentation Phase
In this phase, your application will combine the results retrieved from the document store with the original question and generate a new prompt.
Generation Phase
In the generation phase, your application will send that question to a LLM to generate the final response.
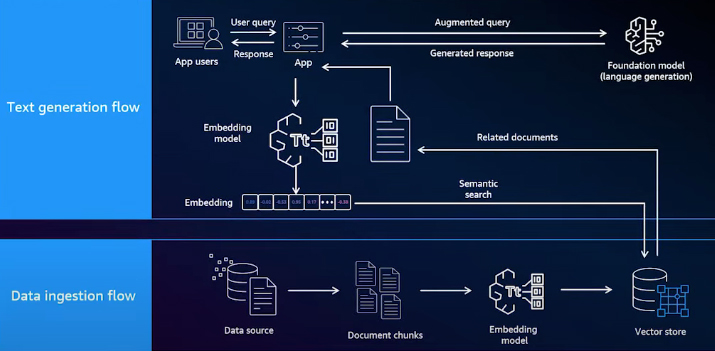
Amazon Bedrock Knowledge Base
You can build this architecture from scratch using your preferred tools and custom code. However, Amazon Bedrock simplifies the process with an offering called the Knowledge Base. During the data ingestion phase, the Knowledge Base supports most text-based file formats. It allows you to choose from different chunking algorithms, embedding models, and vector data stores to create your knowledge base. These configurations can be set up with just a few API calls. Once the knowledge base is built, it is ready for use in your application. At runtime, Bedrock provides three different ways to interact with the knowledge base, allowing you to strike a balance between simplicity and flexibility.
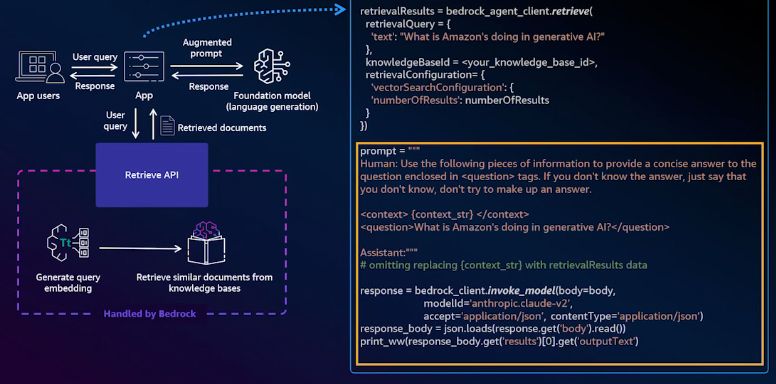
Retrieve API
The first approach is called the Retrieve API, where Bedrock handles the retrieval phase of a RAG process, and your application manages the augmentation and generation phases. When a user asks a question, your application calls the Retrieve API. Bedrock will then embed the question and retrieve the related documents, returning them to your application. Once your application receives these documents, you must create a new prompt that combines the question with the relevant documents.
With the Retrieve API, you write some code, but you gain significant flexibility in controlling the flow and defining the prompts sent to the LLM.
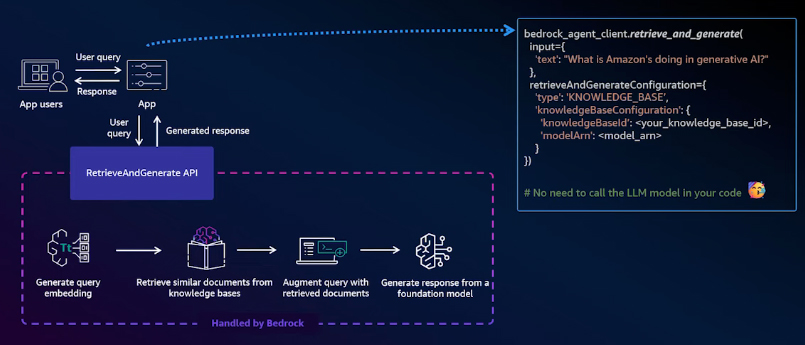
RetrieveAndGenerate API
The second approach for using a knowledge base in your application is the Retrieve and Generate API. With this API, Amazon Bedrock handles all three phases of the RAG process: retrieval, augmentation, and generation. The only code you need to write is a single API call to Amazon Bedrock.
Agent Integration
In this approach, Amazon Bedrock allows you to integrate the knowledge base into an agent workflow. In this setup, the agent can access and utilize the knowledge base to perform tasks, answer queries, or provide assistance, enhancing the agent's capabilities with your organization's proprietary information.
Orchestrate tasks and take actions
Once you have included documents in your application, your support agents can quickly find information from thousands of documents. However, your application is still not integrated with other applications within your organization. As a result, your support agents need to access these systems manually to find relevant data. About 90% of the tasks performed in these other applications are powered by APIs. However, these APIs have not yet been integrated into your application. One solution is to hard-code these integrations, which has been a common approach for a long time and can still work well for many use cases, as it provides complete control over the integration process. If the goal is to create a virtual assistant with a natural language user interface where users can ask questions in natural language, coding every possible integration becomes impractical. Amazon Bedrock can help address this challenge.
Amazon Bedrock includes a feature called agents. Agents leverage LLMs to understand user intentions expressed in natural language and break down the original request into multiple subtasks. Beyond just identifying these tasks, agents also execute them by calling APIs. For developers, the process is simple: you just need to list all the APIs you want Bedrock to access at runtime. When a user submits a question or request, a single API call to the Bedrock agent initiates the process. Also, you can view the full chain of thought tracing generated by Amazon Bedrock and the prompts sent to the LLM. You can even fine-tune these prompts to optimize the performance of your use case.
Model customization
Model customization differs from the other methods in that it involves changing the internal parameters of the LLM rather than supplying external data to it. This decision tree outlines the various methods and helps you determine which approach to use based on your use case. If the task you try to do is simple and the data you send to the LLM is small, it's easy for your application to handle. In this case, prompt engineering is the most suitable approach. On the other hand, if the data you send to the LLM is relatively large and stored in external sources, you will likely consider RAG or agents. The choice between these two depends on what format the data is stored and how it needs to be. If the data is stored in documents and some delay is acceptable, RAG is a good fit. However, if the data is provided via APIs and you require real-time updates, Bedrock agents would be the better option.
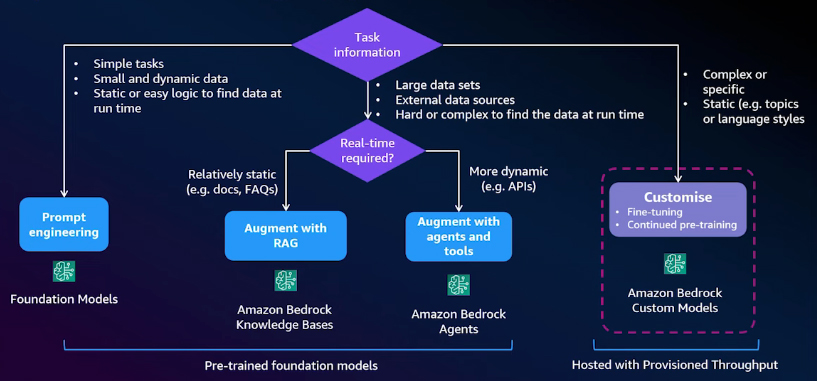
Model customization is useful when the data you provide to the LLM is relatively static and doesn't change often. Examples include organization-specific topics, unique terminologies, or a specific language style used by your organization. In practice, it's generally better to begin with prompt engineering, then explore RAG, and finally consider agents before opting for model customization. The first three approaches offer greater flexibility regarding the data you provide to the LLM and how you provide it.
With model customization, you create a unique model tailored specifically for your business. This gives you full control but also means you are responsible for managing the entire lifecycle of the customized model. Depending on your use case, this could be an advantage or a disadvantage. One significant limitation of model customization is that you cannot easily switch to a different model without undergoing a retraining process.
Reference:
AWS Events
